Researches
Detailed benchmark results across eight scientific domains. Same cognitive architecture — rigorously evaluated with traceable, reproducible evidence.
We screen peptide sequences as toxic vs non-toxic using a post-humanist 5-axis perception (chemical-chromatic · spectral · tactile · topological · synaesthetic; zero learned parameters; 64 dimensions) feeding a Deep MLP head, with the existing AnankeProtocol from the U-CogNet integrated cognitive system (DECT + Reverse Observer + ERA, Friston-style risk evaluator) acting as the safety / governance layer. The pipeline runs over the public ToxinPred-2 corpus (Sharma et al. 2022, Briefings in Bioinformatics), main split, 16,466 peptides.
16,466
76.5 %
−26.5 pp
45
64 / 64
≈ 0.2 M
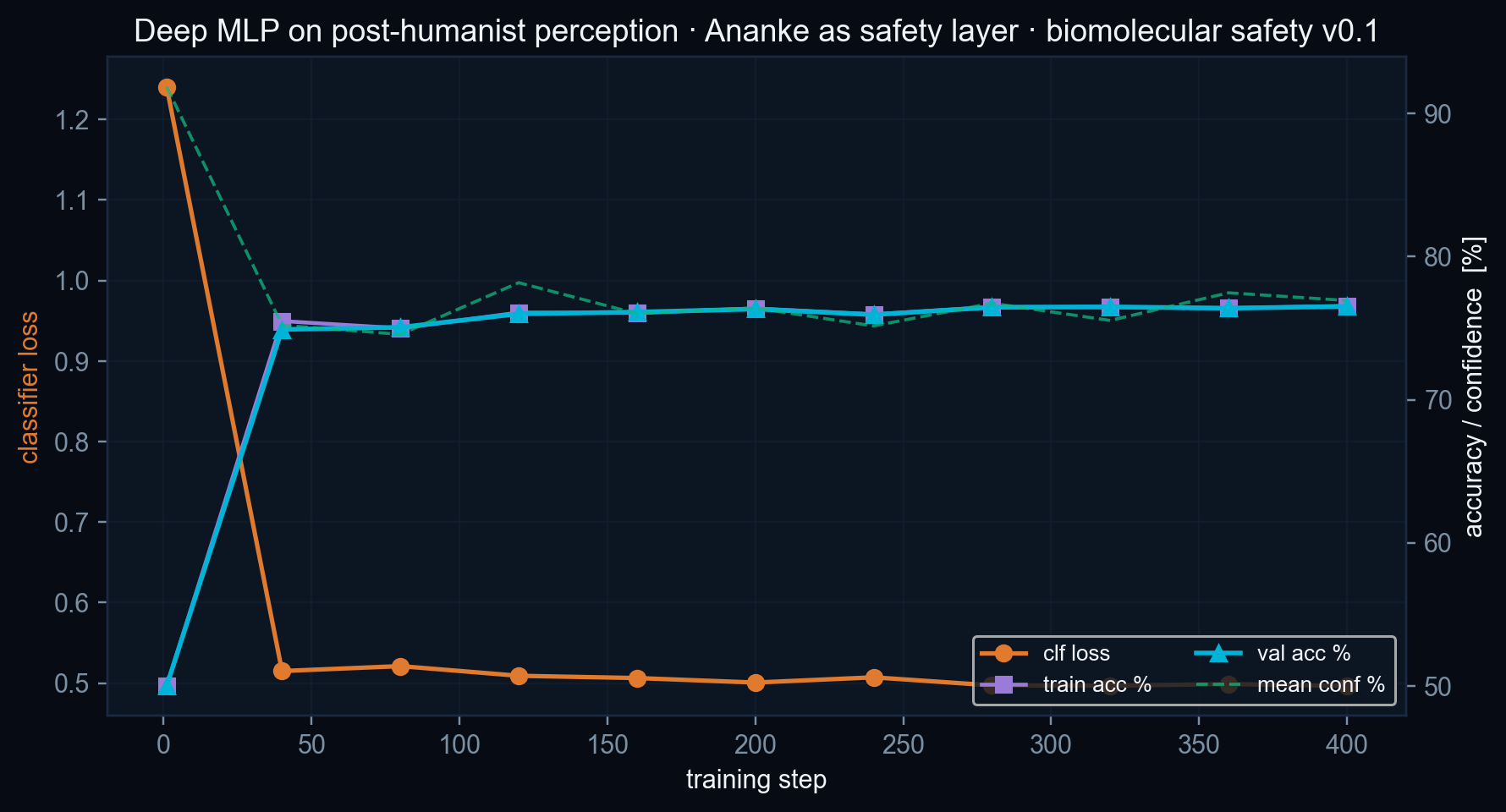
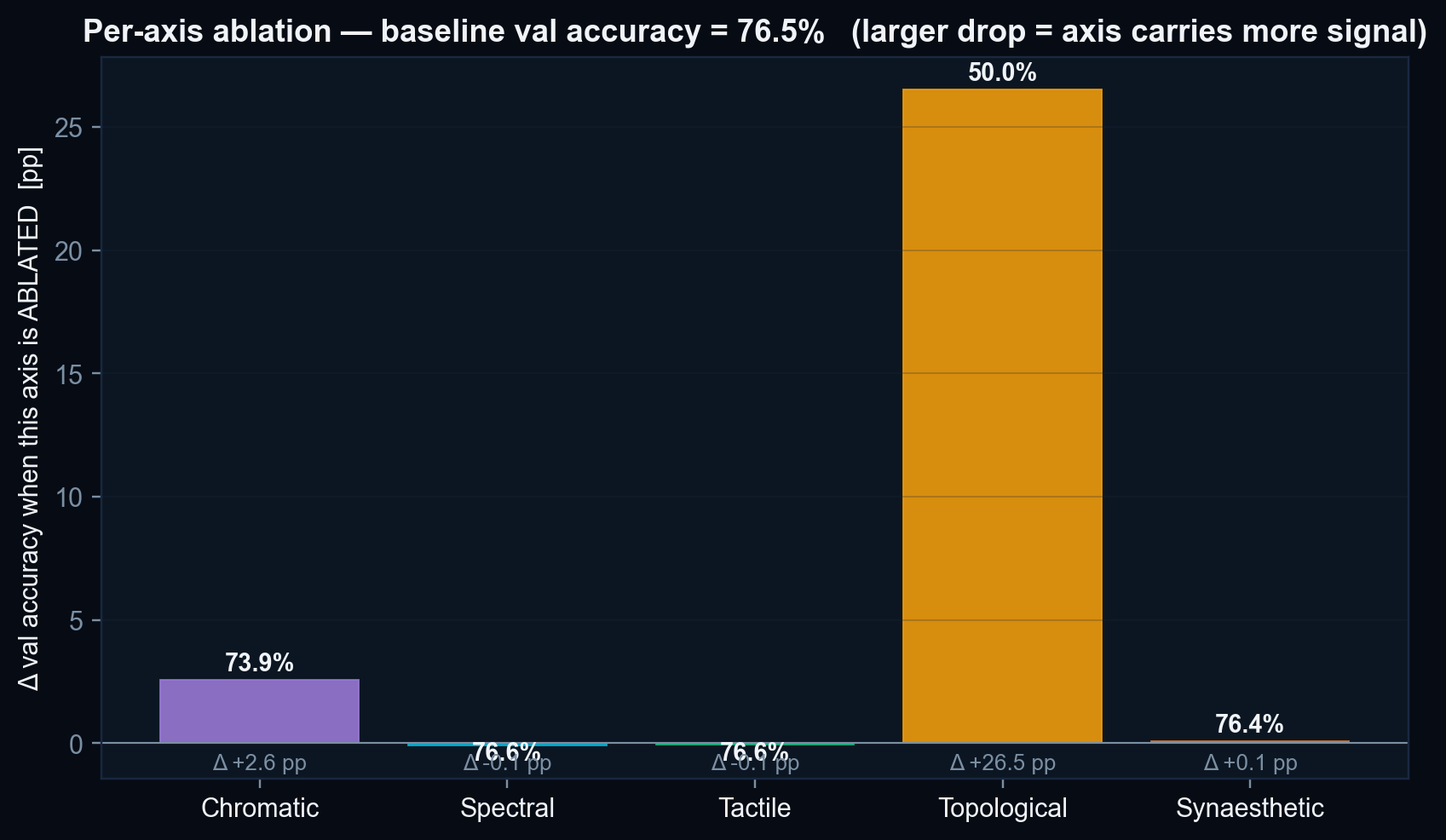
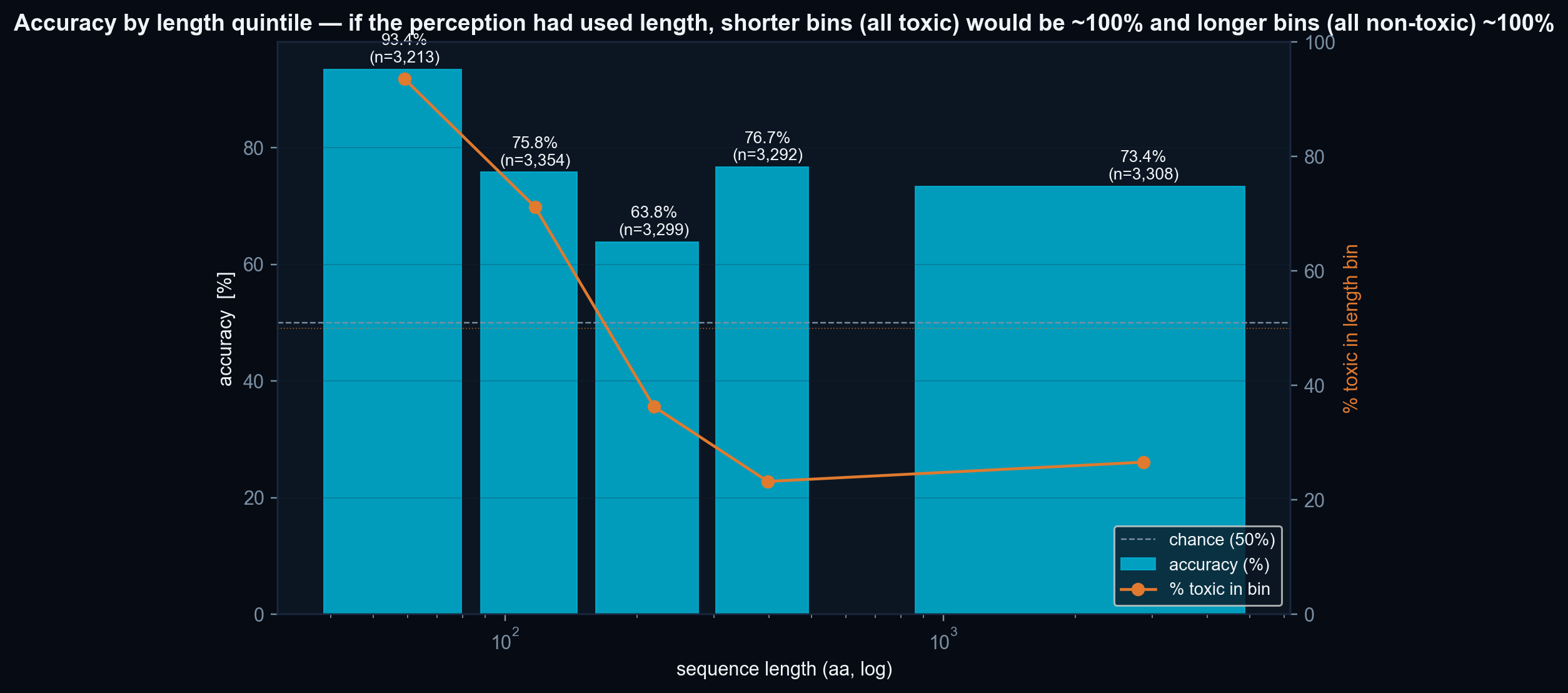
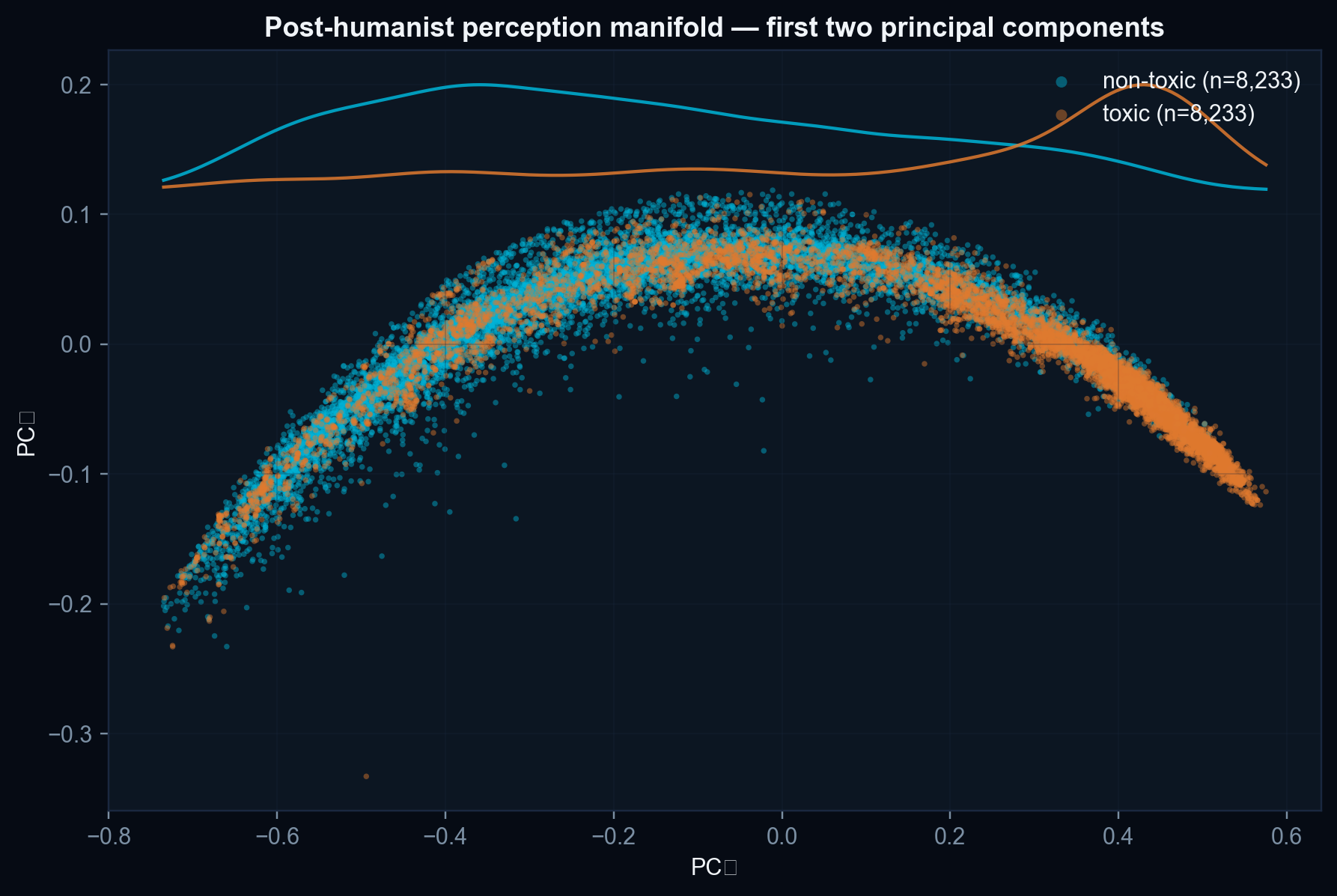
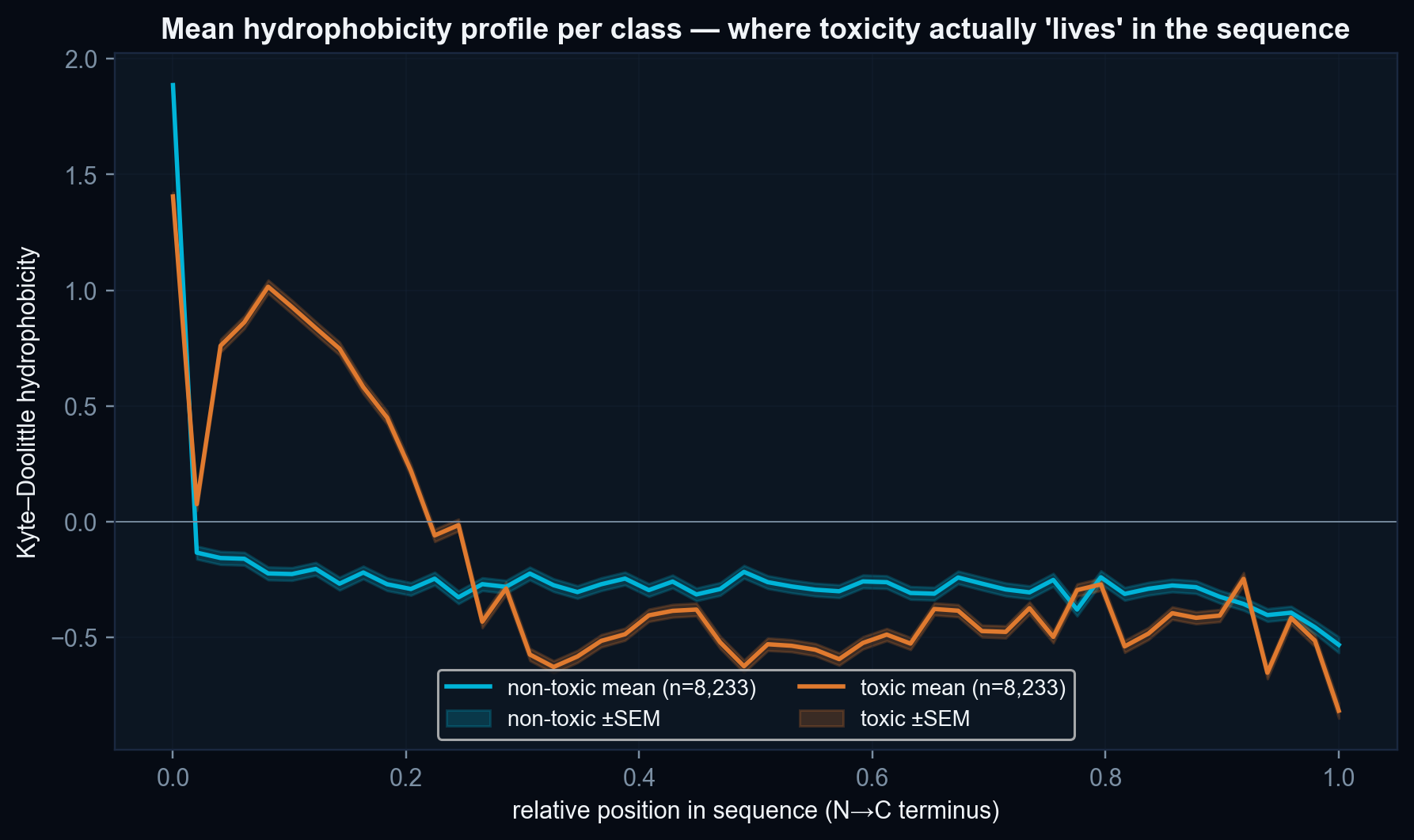
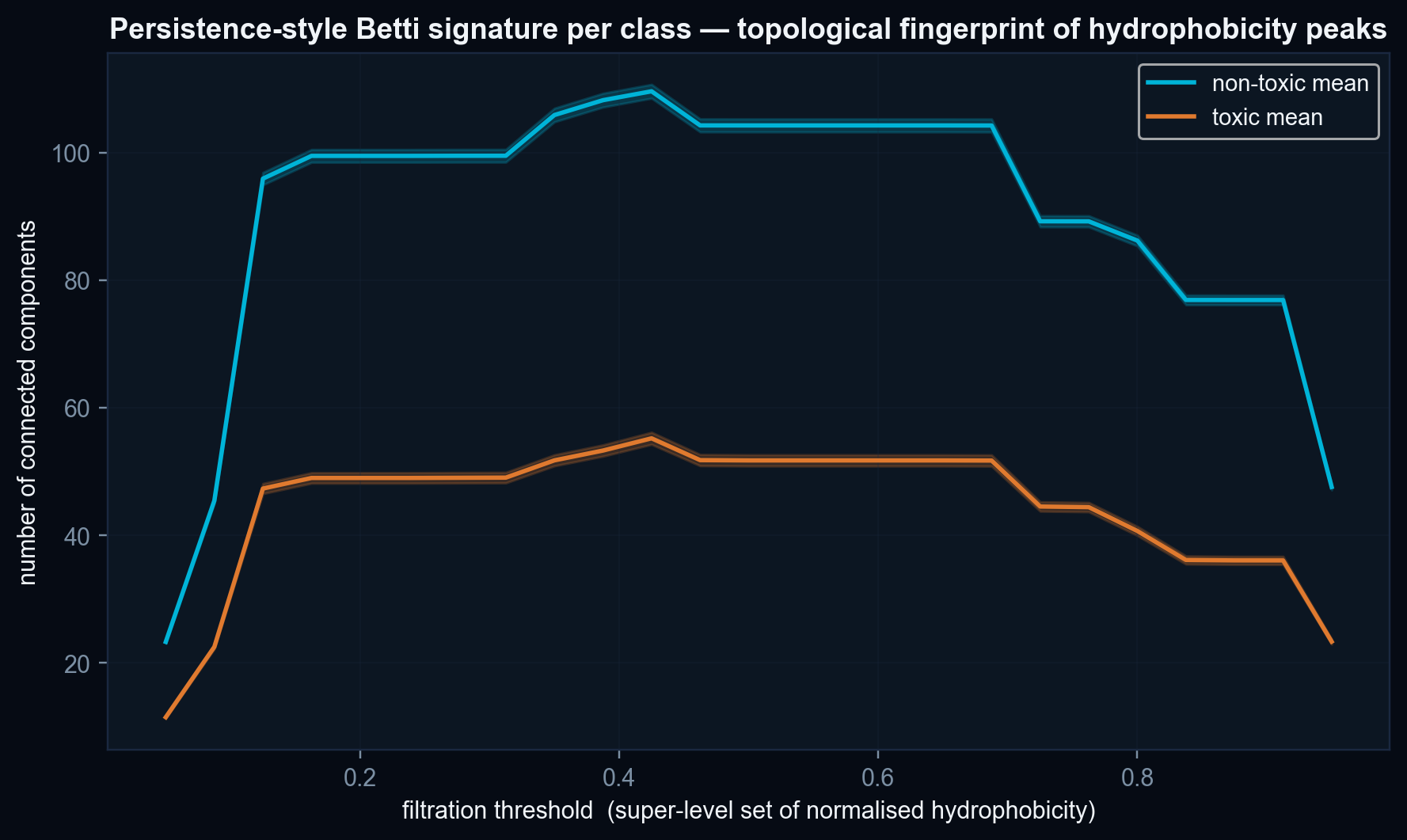
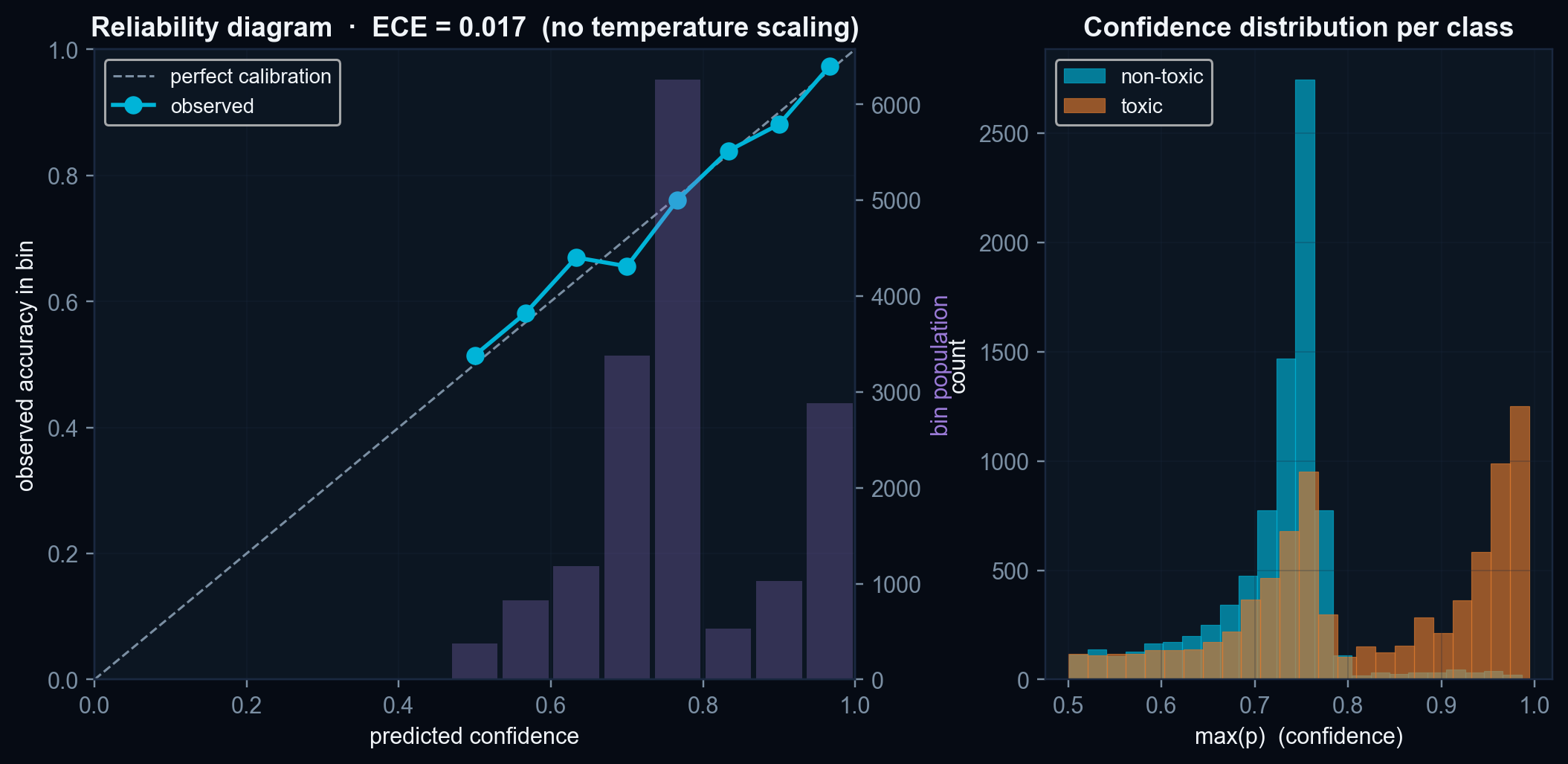
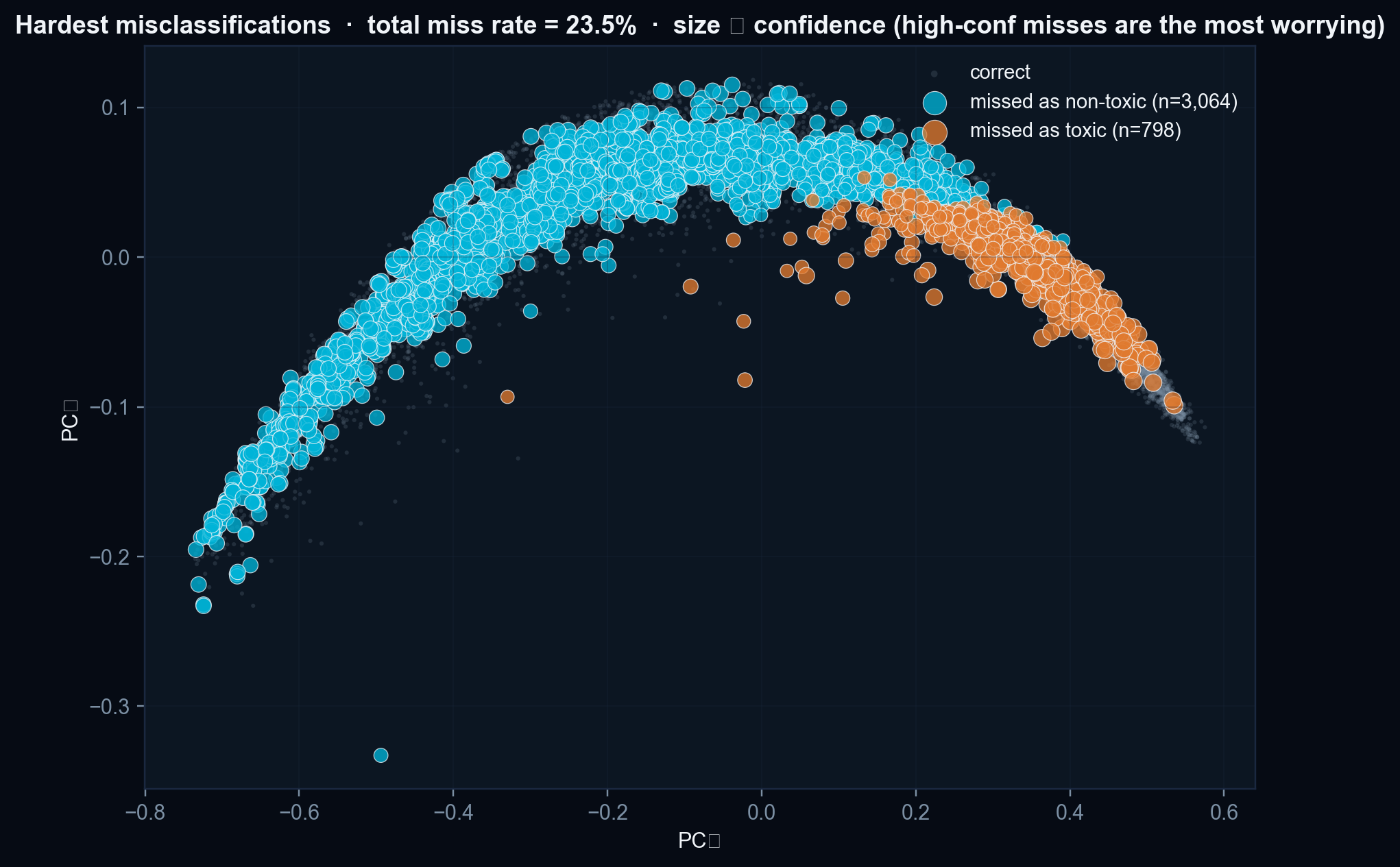
- Length confounder is not fully neutralised. The per-axis ablation shows that ≈ 26.5 pp of the 76.5 % accuracy depends on the Topological axis, which is co-linear with sequence length. The length-stratified accuracy (Figure 3) is the honest discriminative read for the mid-length bins (63–77 %).
- v0.1 is peptide-level only. Synthesis-order screening requires ORF-level reasoning on DNA, which is v0.2 scope (CARD, VFDB, IGSC test sets).
- AnankeProtocol verdicts are uniform allowed at this stage. The protocol is wired in but has no non-trivial state-transition model to evaluate against until the screening service is connected to actual order traffic.
- No external pretrained protein model is used. ESM-2 and similar are deliberately excluded from v0.1 to keep the perception layer interpretable. They remain available as a v0.2 ablation if needed.
References & data provenance
· Sharma, N. et al. (2022). ToxinPred-2 — an improved method for predicting toxicity of proteins. Briefings in Bioinformatics 23 (5), bbac174.· Kyte, J. & Doolittle, R. F. (1982). A simple method for displaying the hydropathic character of a protein. J. Mol. Biol. 157, 105–132.
· Edelsbrunner, H. & Harer, J. (2010). Computational Topology — An Introduction. AMS.
· Guo, C. et al. (2017). On Calibration of Modern Neural Networks. arXiv:1706.04599.
· UniProt Consortium (2024). SwissProt release. Background non-toxic corpus.
· Code, ETHICS statement, and full pipeline at
experiments/biomolecular_safety in the U-CogNet repository.