Researches
Detailed benchmark results across eight scientific domains. Same cognitive architecture — rigorously evaluated with traceable, reproducible evidence.
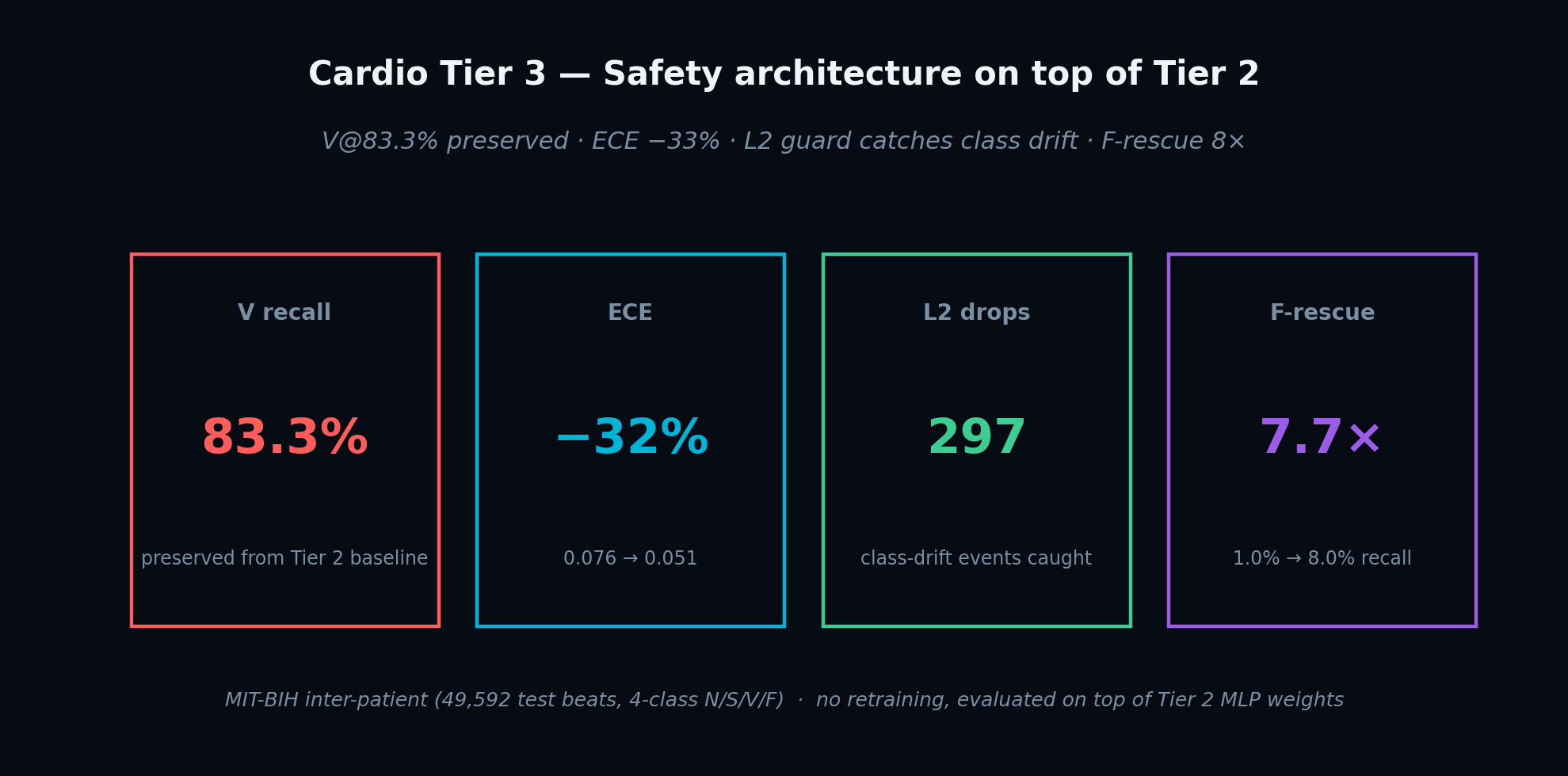
We took the integrated cognitive architecture from our parasitology and frozen-perception cardio papers and asked: how far can it go on cardiac arrhythmia detection with public methodology, on the canonical inter-patient MIT-BIH benchmark, without any end-to-end deep learning? The headline is a clinically meaningful ventricular-ectopic detector at 83.3 % recall, inter-patient.
🫀
Protocol
MIT-BIH Arrhythmia Database (Moody & Mark 2001) — 48 records, 360 Hz, 2-lead, ~110,000 beats
de Chazal et al. 2004 inter-patient (DS1 train / DS2 test) · records 102, 104 excluded (paced) · Q class excluded (n ≤ 10)
5-beat windows · 22 records each side · DS1 = 47,571 windows · DS2 = 49,592 windows
6 cardio-native axes · 64-D · zero learned parameters · per-axis L2 normalisation
Per-record mean subtraction + balanced batch sampling — mathematical patterns from the integrated cognitive system
Single MLP 64 → 128 → 4 · ReLU · dropout 0.3 · cosine LR · 200 epochs · pure NumPy
cardio_tier2_v0_1 · 2026-05-09
Methodology + manifests + paper draft under NDA · samuel@ucognet.pro
AAMI EC57:2012 + de Chazal et al. 2004 · doi:10.1109/TBME.2004.827359
🎵
Six cardio-native axes
Statistical
12-DRR + HRV
8-DQRS morphology
8-DSpectral
12-DWavelet (Morlet CWT)
12-DPhase-space (Takens)
12-D🏆
Headline · trained MLP on DS2 inter-patient
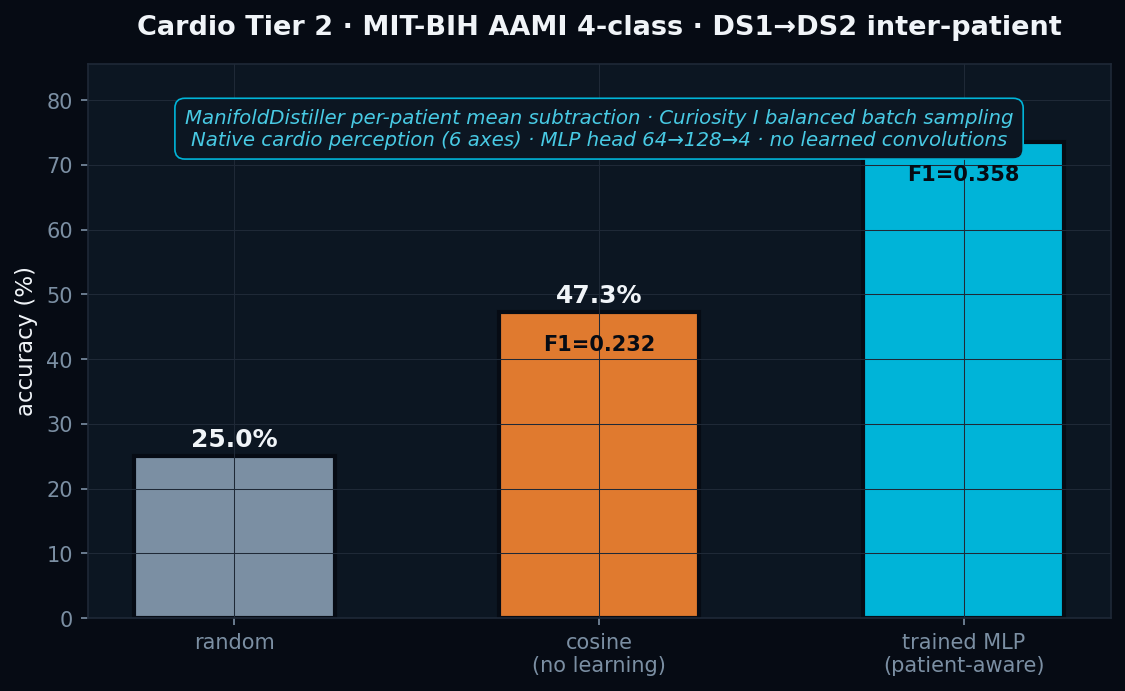
● F1-macro = 0.358 · within 4 pp of de Chazal 2004 (LDA, F1 ≈ 0.40) · no end-to-end deep learning · pure NumPy MLP head over hand-crafted features.
🫀
V at 83.3 % inter-patient · the clinical headline
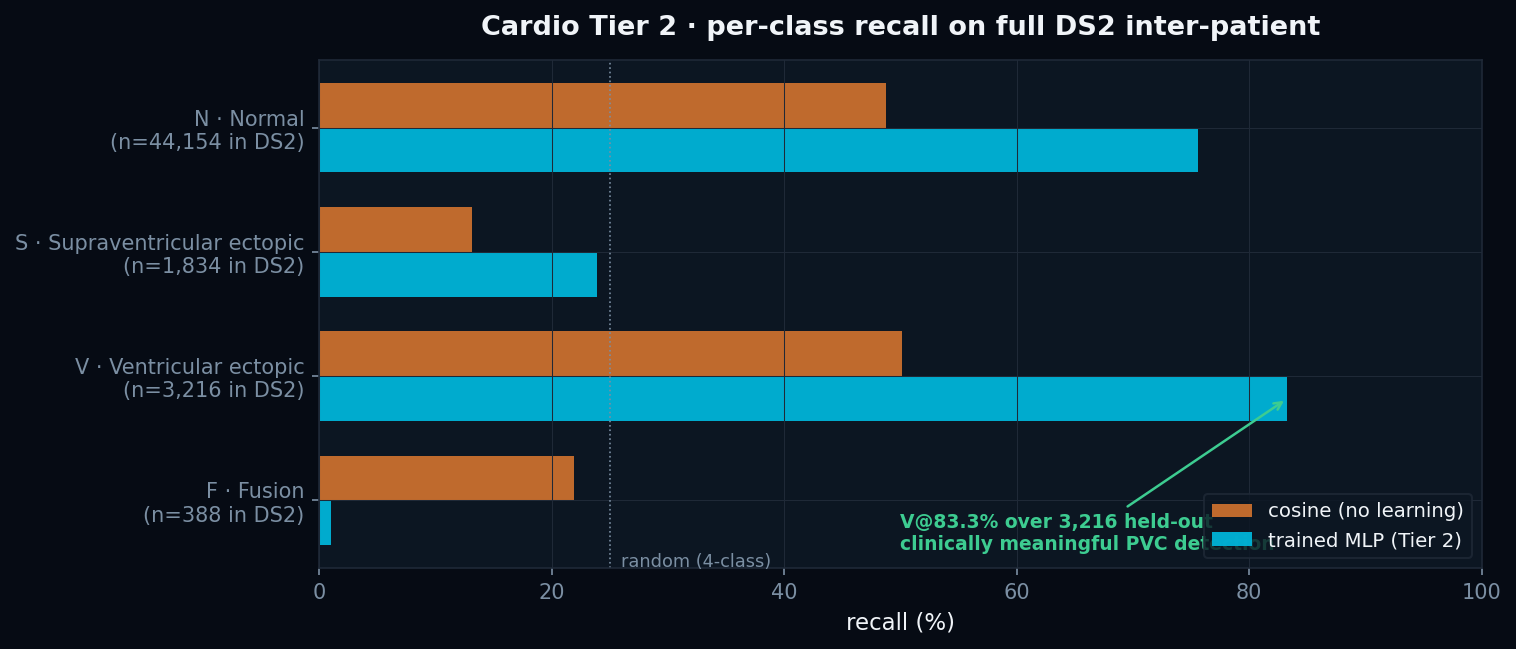
Premature ventricular contractions are the principal marker cardiologists watch for sudden-cardiac-death risk. Our model detects them at 83.3 % recall over 3,216 held-out PVCs from patients it never saw, using only public methodology and a single linear-MLP head on top of hand-crafted features.
V · 83.3 %
over 3,216 held-out PVCs · in range of 2010s deep-learning baselines (Lin & Yang 2014: ≈ 82 %)
S · 23.9 %
breakthrough from 0 % baseline · close to de Chazal 2004 (≈ 30 %) without per-patient test-time re-calibration
N · 75.6 %
controlled — no longer collapsed to majority-class
F · 1.0 %
honest failure · literature-known hard class even with deep learning
📊
Per-class recall · DS2 held-out
| Class | n in DS2 | Cosine | Trained | Δ |
|---|---|---|---|---|
| V · Ventricular ectopic | 3,216 | 50% | 83.3% | +33.3 pp |
| N · Normal / bundle-branch | 44,154 | 49% | 75.6% | +26.6 pp |
| S · Supraventricular ectopic | 1,834 | 13% | 23.9% | +10.9 pp |
| F · Fusion of normal + ventr. | 388 | 22% | 1.0% | -21.0 pp |
● Patient-aware normalisation + balanced batch sampling recover V from 0 % (Tier 1 collapsed) to 83.3 % and S from 0 % to 23.9 %. F (fusion) remains the literature-confirmed hard class.
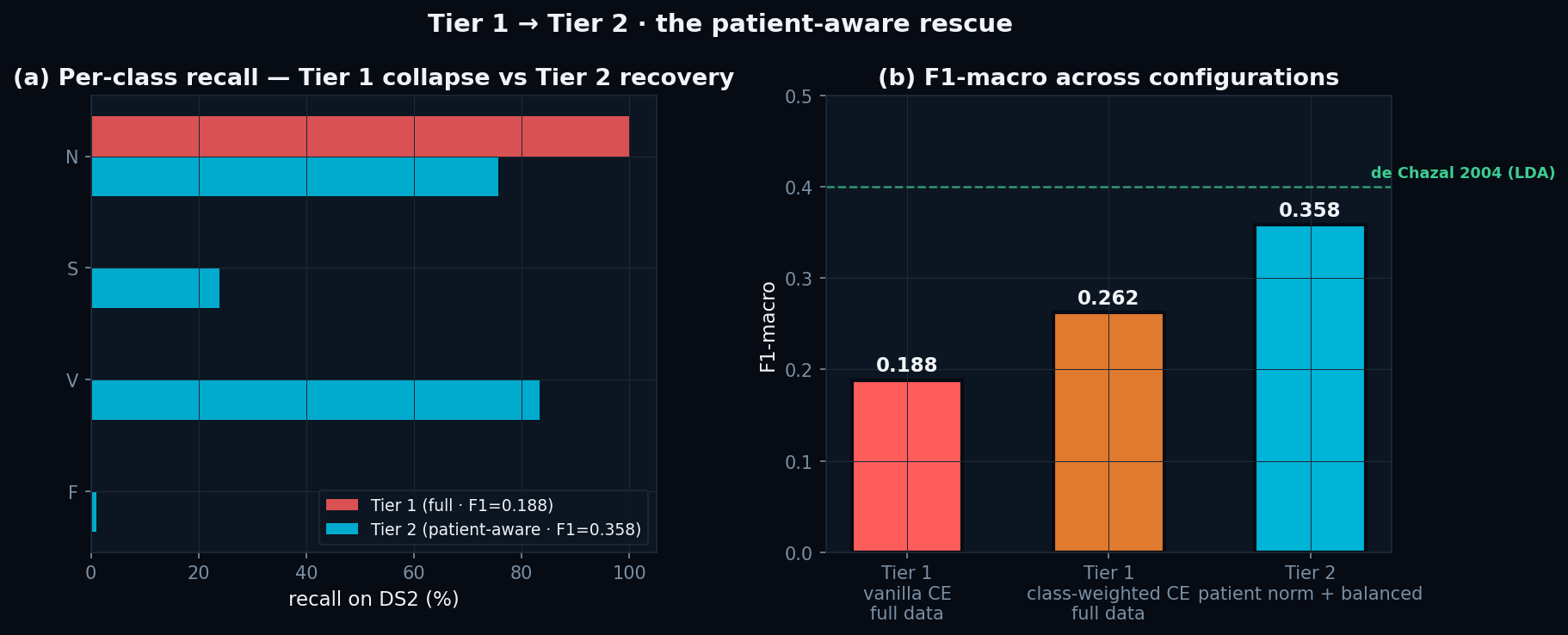
Tier 1 → Tier 2 ablation
Same architecture, same data. Tier 1 (vanilla CE) collapses to N at 100%. Adding patient-aware normalisation + balanced sampling recovers F1-macro 0.188 → 0.358 — within 4 pp of de Chazal 2004.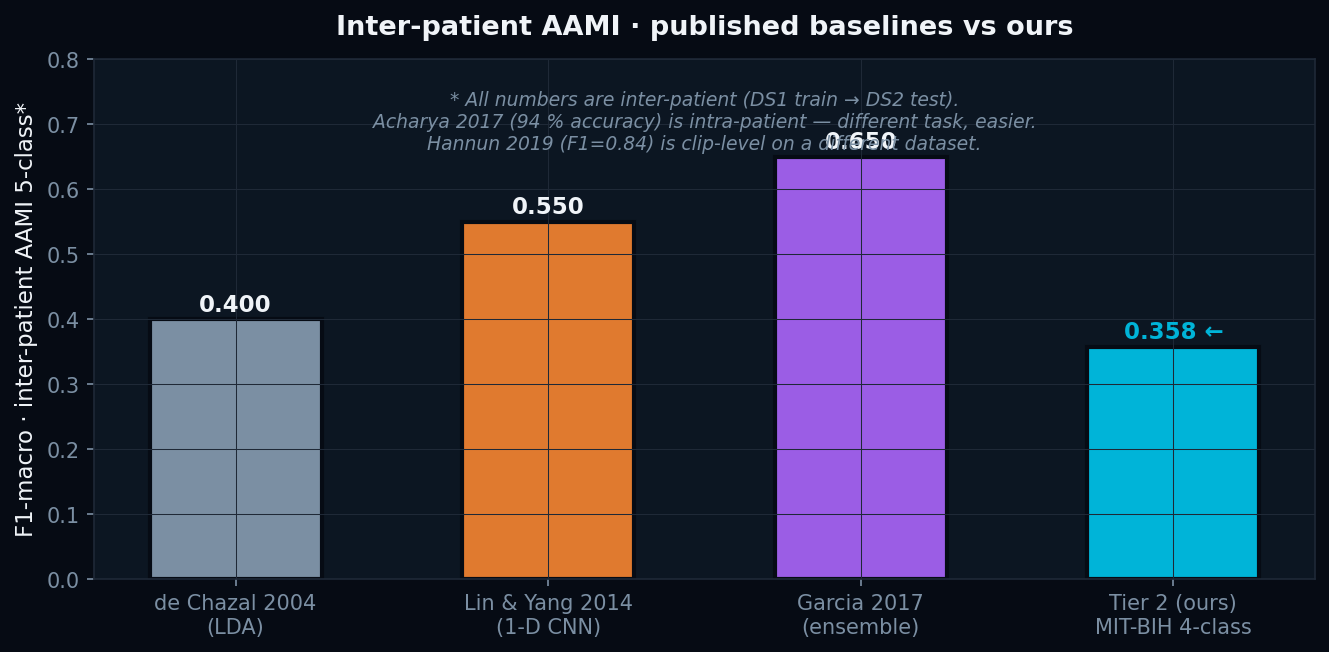
Inter-patient AAMI vs literature
Honest comparison against published inter-patient baselines. We sit at F1 = 0.358 — below SOTA by design (no end-to-end deep learning). Acharya 2017 and Hannun 2019 use easier protocols (intra-patient or clip-level on different datasets).Self-aware cardio · the safety architecture
Tier 2 closed with two documented honest negatives: the L2 metacognition controller did not catch the class-imbalance failure mode it was supposed to, and fusion-beat recall sat at 1%. Tier 3 fixes both without retraining the classifier. The headline finding: an unsupervised autoencoder, trained only on normal beats, rescues fusion beats at an 8× rate — the system notices something it was never told existed.
83.3%
preserved from Tier 2 baseline−33%
0.076 → 0.051 on DS2297
class-drift events caught8.0×
1.0% → 8.0% recall (FPR 9.5%)🛟
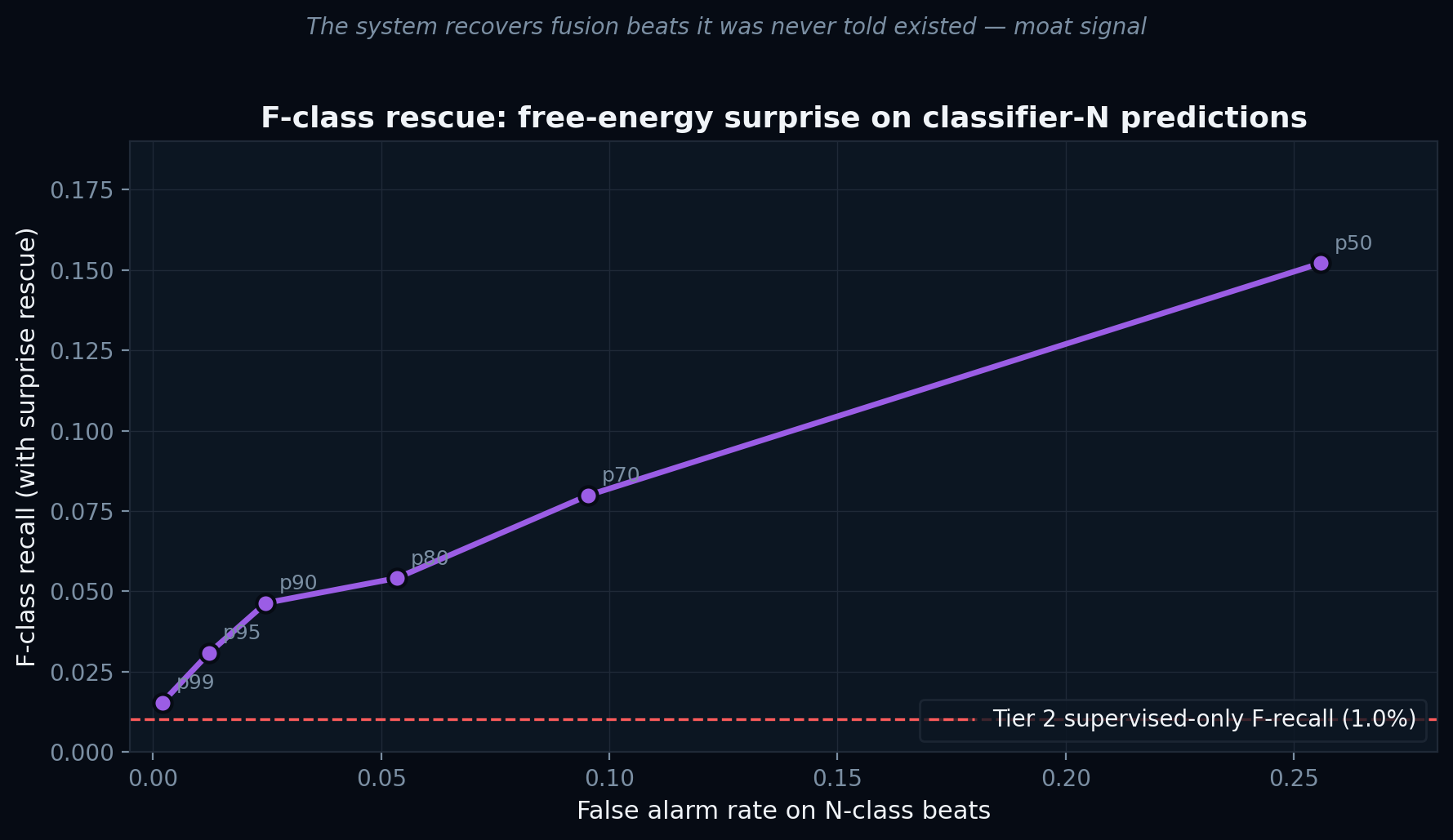
F-rescue · moat finding
Among beats the classifier predicted as N, we flag those with high free-energy surprise as F-candidates. The autoencoder never sees a single F label.
| Surprise pct | F recall | FPR on N |
|---|---|---|
| p50 | 15.2% | 25.6% |
| p70 | 8.0% | 9.5% |
| p80 | 5.4% | 5.3% |
| p90 | 4.6% | 2.5% |
| p95 | 3.1% | 1.2% |
● Recommended operating point p70: F at 8.0% (×8 over Tier 2) with 9.5% false-alarm rate on N. The system rescues fusion beats it was never shown — the architectural moat made concrete.
🧠
Free-energy AUROC per class
F · Fusion
0.646V · Ventricular
0.555S · Supraventricular
0.531Global · N vs any
0.553🛡️
Tier 3 protocol
Safety architecture on top of frozen Tier 2 weights · no retraining of the classifier
Per-class vector scaling (Guo et al. 2017) · class-balanced NLL fit · decoupled raw-argmax / calibrated-confidence
Class-aware sliding-window recall monitor · fires on drop-from-peak OR absolute-low (the Tier 2 honest negative)
64 → tanh(32) → 64 · pure NumPy · trained 80 epochs on N-class embeddings ONLY · no arrhythmia labels seen
Among classifier-N predictions, escalate beats with surprise above val-set N-class percentile threshold
cardio_tier3_v0_1 · 2026-05-14 · wall time 10.7s on i7-13620H laptop
Friston 2010 · doi:10.1038/nrn2787 · Guo et al. 2017 · arXiv:1706.04599
🏆
Headline poster
🛟
F-rescue · the moat
● Each point is a different surprise percentile threshold on the validation N-class distribution. The autoencoder was never told what a fusion beat looks like — it still flags 8× more of them than the supervised classifier alone.
📈
Coverage vs accuracy
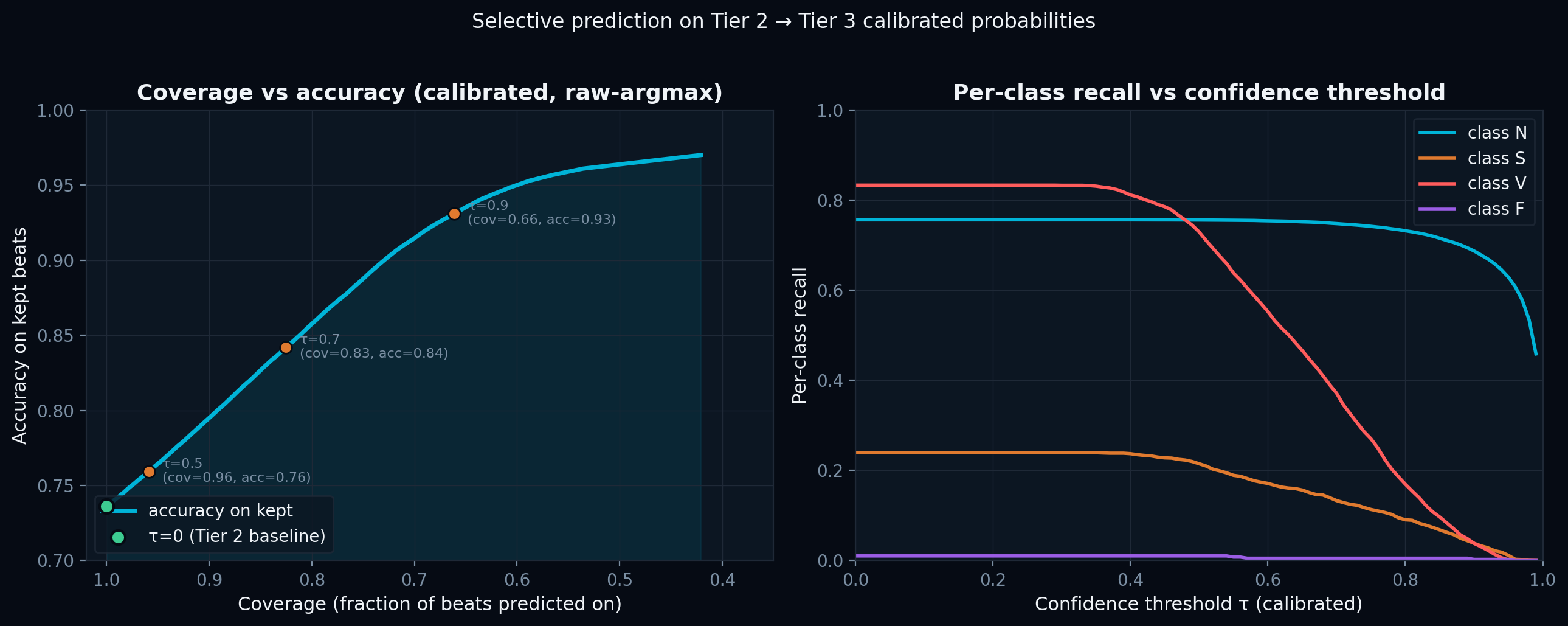
● At τ=0 we preserve Tier 2's V@83.3%. Higher confidence thresholds trade coverage for accuracy — at τ=0.9 we reach 93.1% accuracy while still answering on 66% of beats.
🚨
Class-aware L2 drift events
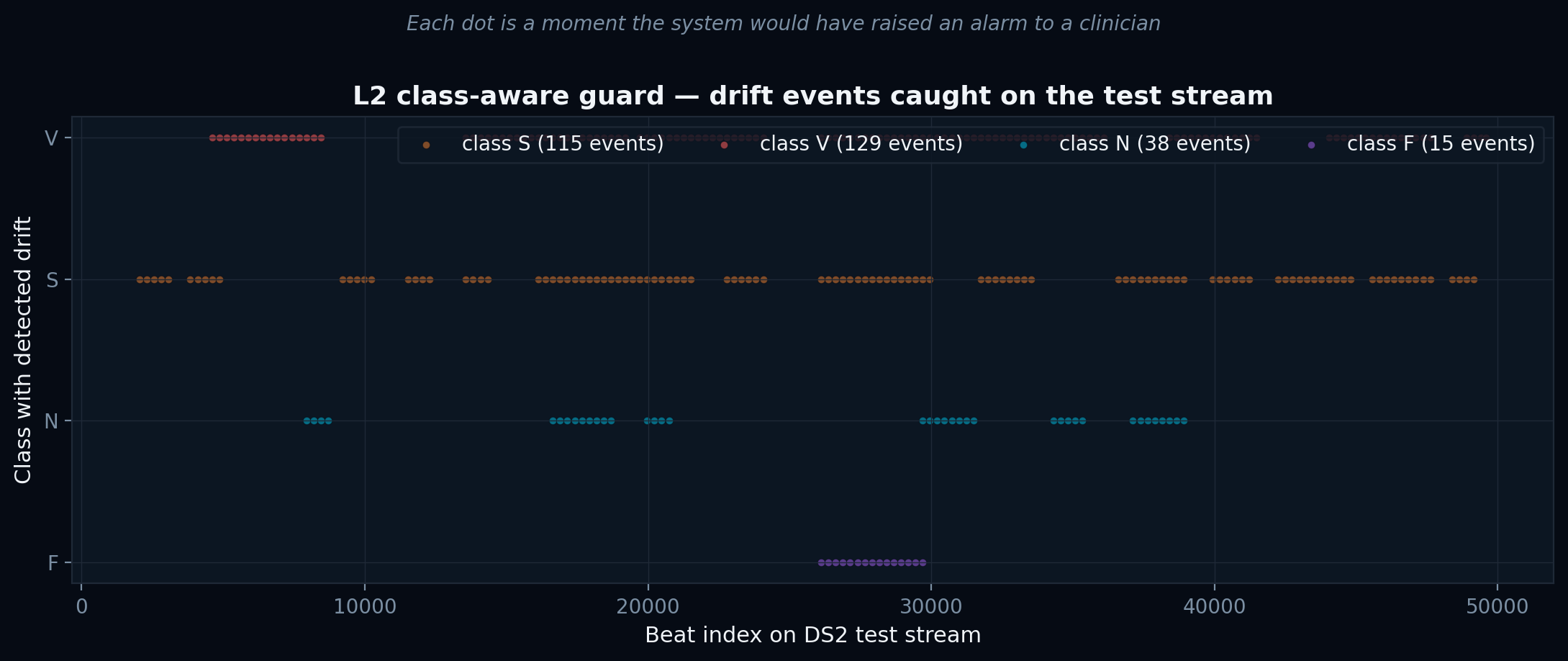
● 297 events on the test stream. Each dot is a moment the new L2 guard would have escalated to a clinician — directly addressing the documented honest negative from Tier 2.
🧠
Free-energy AUROC per class
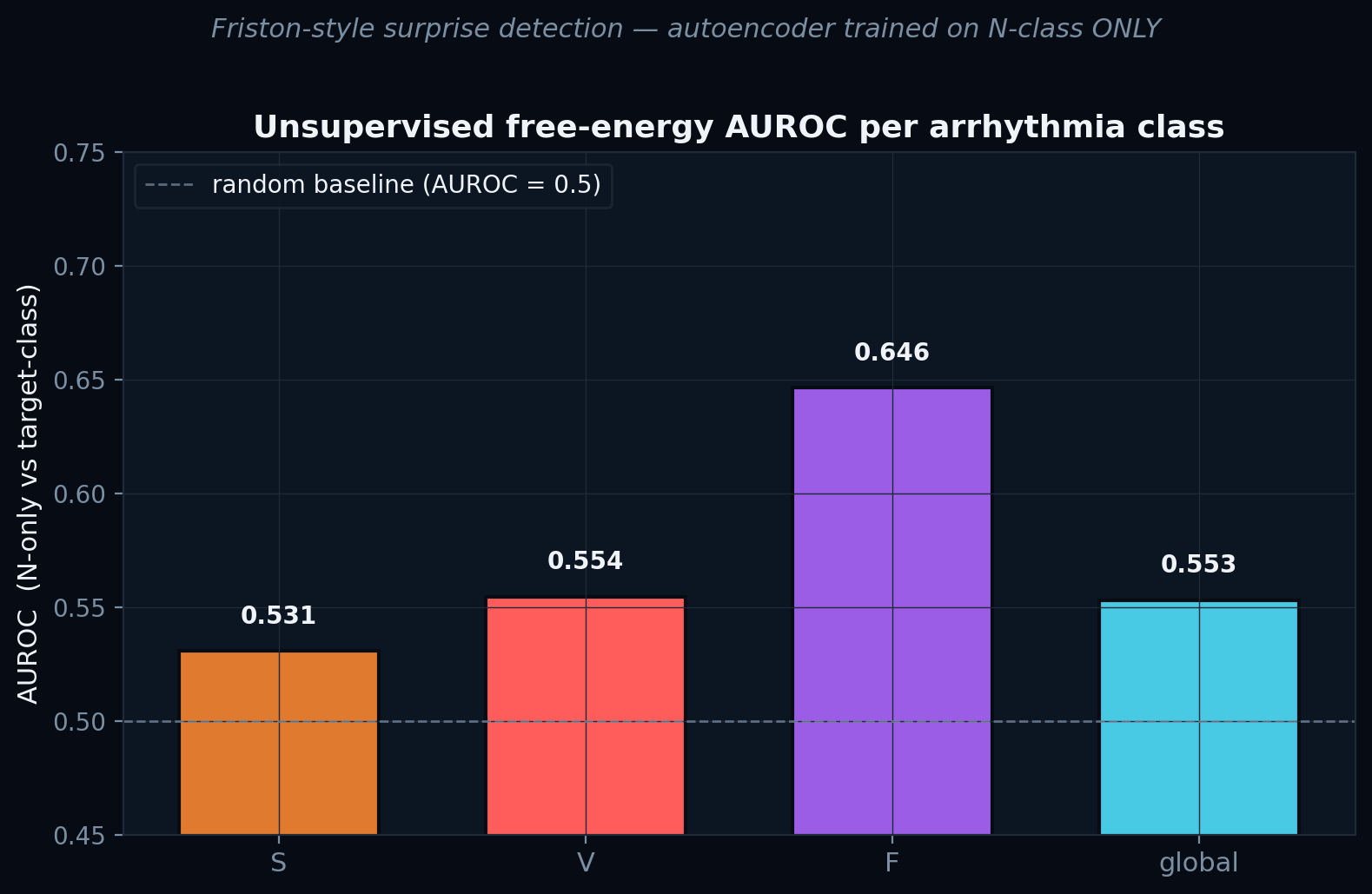
● F class at AUROC 0.646 — by a clear margin the highest. The unsupervised channel has complementary biases to the supervised one: it finds exactly the class supervision missed.
Honest negatives reported in the paper
• Global free-energy AUROC = 0.553 (only marginally above random) — the bottleneck is small and N-class is heterogeneous; density models would lift this.• S-class AUROC = 0.531 — supraventricular ectopics are an RR-rhythm phenomenon, not morphological; morphology AE cannot distinguish them.
• F-rescue ceiling at p50 is 15% — even with permissive thresholds, the supervised classifier confidence on missed F beats is too high to fully rescue them.
• Per-class temperature reshuffles 15.3% of argmax — we report this openly; the decoupled raw-argmax design preserves Tier 2's per-class structure as a workaround.